4. Twitter API
Posted: May 2, 2016; Updated: May 2, 2016
In this project the 5000 tweets were pulled from #fridayreads using Twitter API in R. The library 'twitterR' was used. After downloading the tweets the data was cleaned largely using 'regex'. Several special cases were removed by individual commands. The downloaded tweets and code is uploaded on my Github respository.
Questions asked:
- Which are the top authors?
- Which are the top books read?
- Which are the top trending hastags?
- Can you identify bots in the tweets?
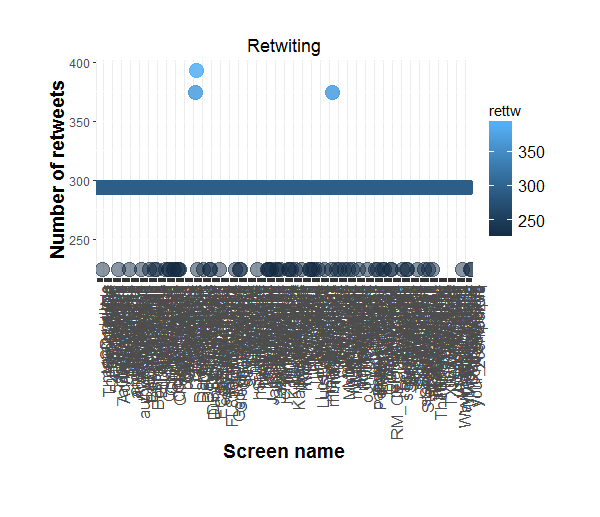
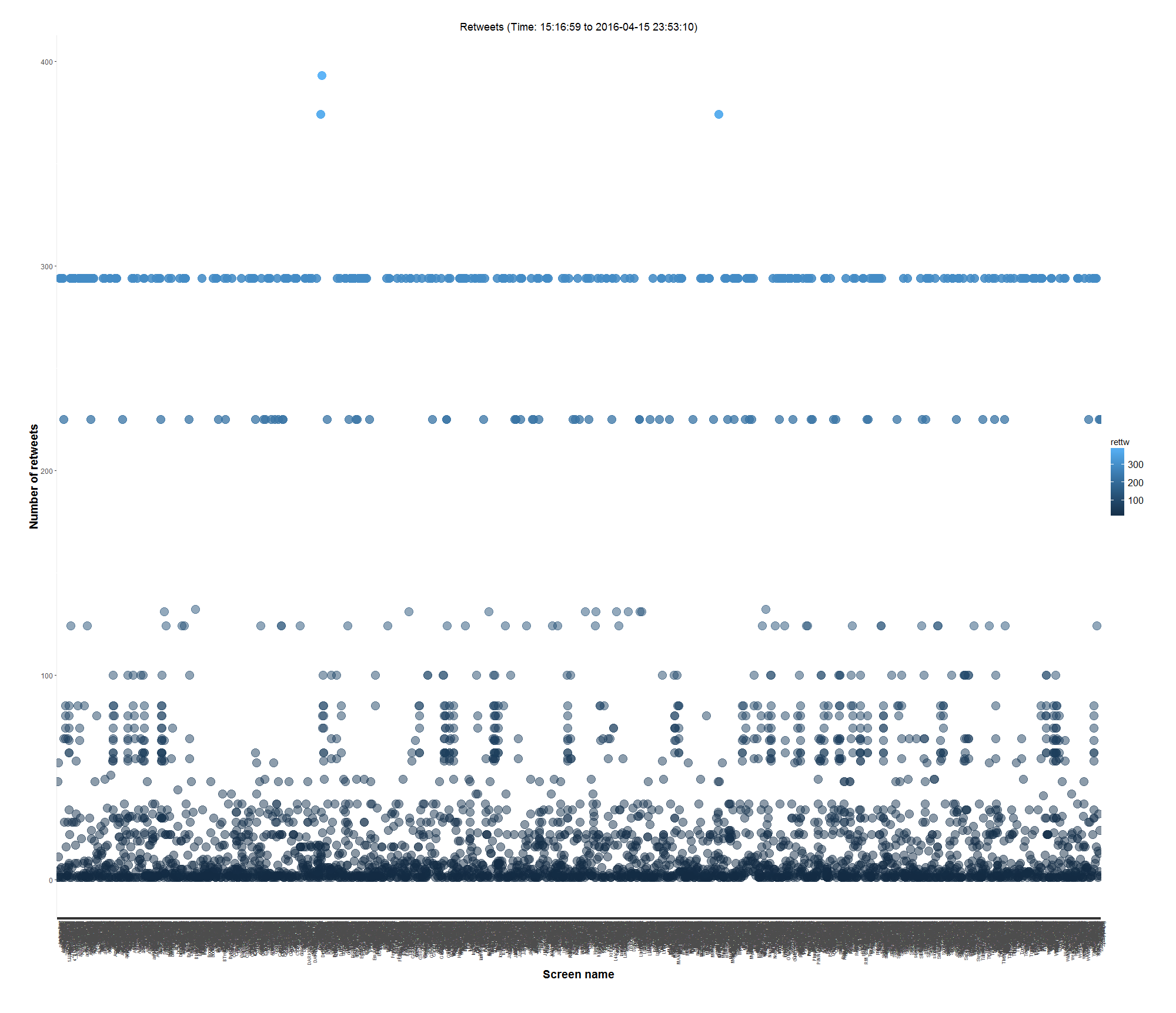
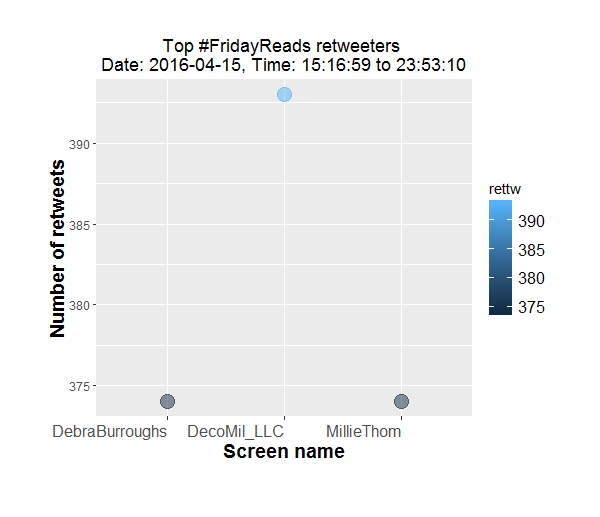
- Any top re-tweeters?
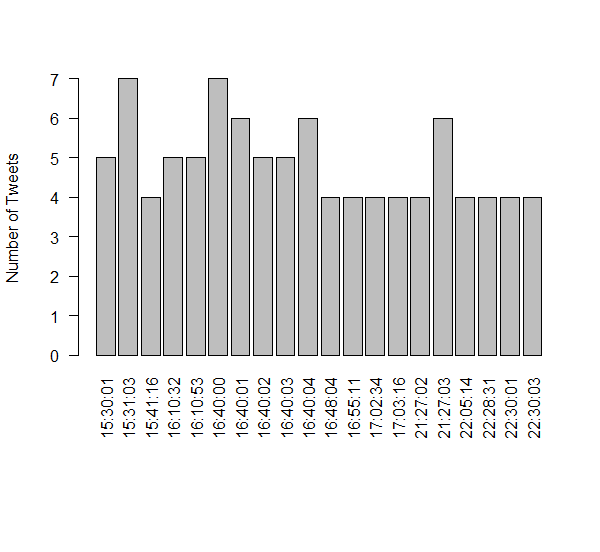
- Frequency of tweets with time?
Possible answers:
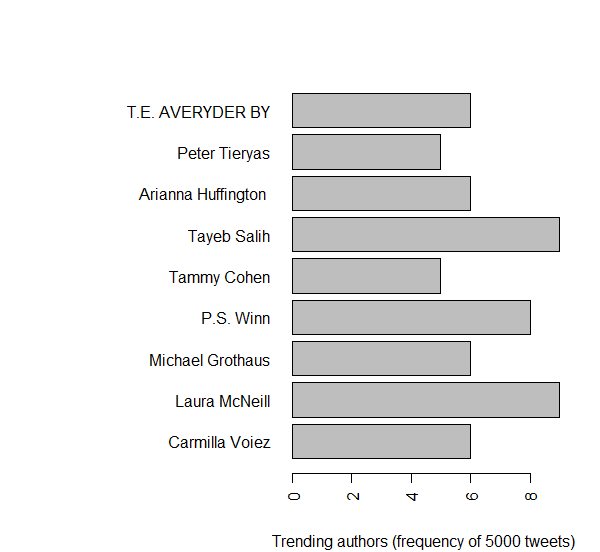
- Top authors were: Laura McNeil, Tayeb Salih, P. S. Winn
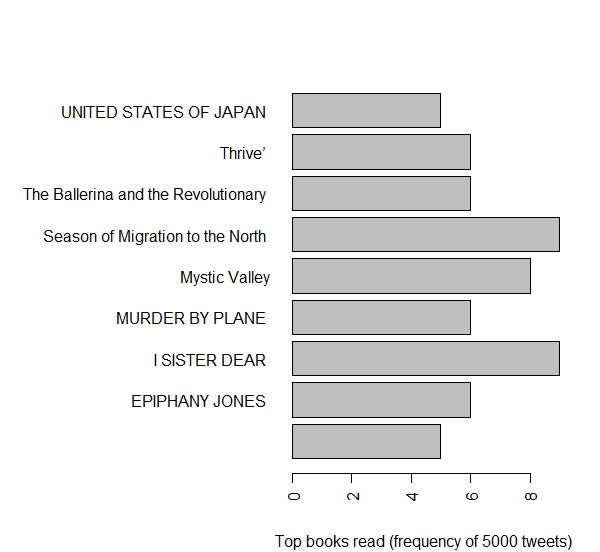
- Top books read: I Sister Dear, Season of Migration to North, Mystic Valley
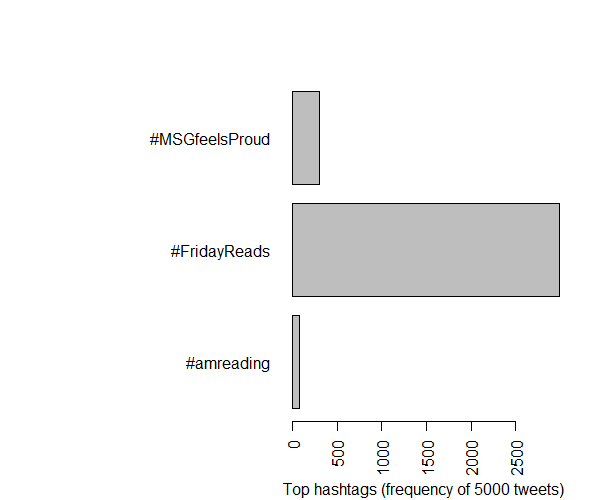
- Top hastags: #MSGfeelsProud, #amreading (excluding #fridayreads which was highest)
- Any bots: Yes, atleast two bots were identified
- Top retweeter: DeoMil_LLC
- Frequency of tweets: The tweets were higher between 3:00 pm to 4:00 pm on Friday as compared to time between 5:00 pm to 10:00 pm
Sample code:
# Code to download tweets
consumer_key <- 'xxxx'
consumer_secret <- 'xxxx'
access_token <- 'xxxx'
access_secret <- 'xxxx'
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
# download tweets to a variable
tgif <- searchTwitter("#FridayReads", n=5000, since='2016-04-08')
# Cleaning the data
df2 <- as.data.frame(df$text)
df3 <- df2[grep(" [Bb][Yy] ", df2[,1]),]
df3 <- as.data.frame(df3)
df4 <- df3
colnames(df3) <- c('books')
df3$books <- as.character(df3$books)
df3$books <- gsub("^RT @.*:\\s+", "", df3$books)
df3$books <- gsub("https://.*?$", "", df3$books)
df3$books <- gsub("#(.*?):", "", df3$books)
df3$books <- gsub("#(.*?) ", "", df3$books)
df3$book_name <- gsub("by.*", "\\1", df3$books)
df3$author <- gsub(".*by", "\\1", df3$books)
df3$author <- gsub("#.*", "", df3$author)
df3$author <- as.character(df3$author)
df3$author <- gsub("@", "", df3$author)
df3$book_name <- gsub("#.*", "", df3$book_name)
#n <-gsub("^(\\w+\\s\\w+).*$", "\\1", df3$author)
#df3$au <- gsub("((\\w+\\W+){0,9}\\w+).*", "\\1", df3$author)
df3$author <- gsub("((\\w+\\W+){1}\\w+).*$", "\\1", df3$author) #wont work with "^"
df3$book_name <- gsub("&", "", df3$book_name)
df3$author <- gsub("&", "", df3$author)
df3$book_name <- gsub("@the_author_", "", df3$book_name)
df3$book_name <- gsub("@(\\w+|\\W+)\\s", "", df3$book_name)
#df3$book_name <- gsub("<.*", "", df3$book_name) #won't work as these are non-english characters
df3$book_name <- gsub("\\[.*?\\]\\s", "", df3$book_name) #remove '[video]'
df3 <- df3[!grepl("RT", df3$book_name),] #delete eows with 'RT'
#df3 [df3 ==""] <- NA #fill empty cells with NA
Figure gallery: